Cygwin なんでも掲示板
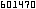
一覧 | 最新記事 | 過去一覧 | 検索 | FAQ | アンテナ | HOME(新規投稿・発言はできません)
▼スレッド
│
└◇871:wget で再帰回収 [shige] 12/26 11:31
└◇872:Re:wget で再帰回収 [な] 12/26
└◇905:Re[2]:wget で再帰回収 [shige] 01/08
└◇906:Re[3]:wget で再帰回収 [な] 01/08 <
wget で robots.txt や meta tag のロボット制御を無視させたいのですが、man wget を見た限り、設定ができないようです。スレッド一覧
Cygwin バイナリ, tar ball からの make ともに試しましたが、オプションそのものがないように見受けられます。(strings `which wget` | grep robot)
やりたいことはいわゆる丸ごとダウンロードなのですが、目的は、Web サイトのコンテンツの圧縮ソフトを作ったので、よそ様のサイトでどれくらいの効果があるか、測定したいのです。
curl は再帰回収自体ができませんし、何か代替手段がありましたら、ご教授いただけませんでしょうか。wget 自身の改造を試みたのですが、どうもうまくいきませんでした。
というか、wget -r -L -l 10 url のように -l を指定すると私のところでは正常に再帰回収しないようなのです。バグ? MD5 は、70f0043044029bbbff271a5f5aad169d です。
アドバイスよろしくお願いいたします。
> Cygwin バイナリ, tar ball からの make ともに試しましたが、オプションそのものがないように見受けられます。(strings `which wget` | grep robot)スレッド一覧
そんなばかな。
$ mkdir tmp
$ cd tmp
$ tar jxf $cygwin_archive/wget/wget-1.8.2-2.tar.bz2
$ cd usr/bin
$ strings wget.exe | grep robot
robots
robots
Not following %s because robots.txt forbids it.
/robots.txt
Loading robots.txt; please ignore errors.
$
となりましたが?
info wget はご覧になりましたか?
> というか、wget -r -L -l 10 url のように -l を指定すると私のところでは正常に再帰回収しないようなのです。バグ? MD5 は、70f0043044029bbbff271a5f5aad169d です。
wget --help の内容はご覧になりましたか?
'-L' オプションの意味は理解されていますか?
なさん、ご回答いただきまして、ありがとうございます。スレッド一覧
-L には、follow relative links only とありますが、英語をそのままの意味で理解するなら、相対リンクのみをたどる、となりますが、この理解に誤りがあるのでしょうか? 浅学のため、動作しない理由がわかりかねます。なさんがご存知の、follow relative links only 以上の、再帰回収ができない理由、もしくは、もうちょっとヒントを教えていただけますでしょうか。
先にも書いたとおり、とあるサイトのデータ (の一部) を再帰的に取得したいので、そこから、外部に張られているリンク (相対リンクではない絶対リンク) をたどって欲しくないという意味で、-L を追加したものです。
ちなみに、Wget を使おう的ページ (http://www.geocities.jp/horiuchimasaru/wget.html) では、応用として、
wget -r -L -l 10 http://seagull.cs.uec.ac.jp/~horiuc-m/index.html
http://seagull....を再帰回収(-r)で相対リンクだけ(-L)をたどり 深さ10まで(-l 10)でダウンロードする。 HTTP(ホームページ)の場合はこの使い方が一般的。
として、私とまったく同じ引数並びで紹介されています。
strings /usr/bin/wget.exe | grep robot の結果は、なさんと同じでした。おそらく、自分で、robot まわりの関数をすべて削って改造した wget に対して string をとったのかもしれません。
少なくとも、md5 hash が異なっていますから。
> -L には、follow relative links only とありますが、英語をそのままの意味で理解するなら、相対リンクのみをたどる、となりますが、この理解に誤りがあるのでしょうか? 浅学のため、動作しない理由がわかりかねます。なさんがご存知の、follow relative links only 以上の、再帰回収ができない理由、もしくは、もうちょっとヒントを教えていただけますでしょうか。スレッド一覧
相対リンクのみを辿る、ということは、相対パス表記のリンクのみを辿ると
いう意味です。
たとえば<a href="foo/bar">は辿るけれども、<a href="/path/to/foo/bar">と
いうようなリンクは辿らない、ということになります。
取得対象のサイトのリンクが上記のように絶対パスで記述されているなら、
-L オプションで相対リンクのみに制限すると再帰取得を行わないはずです。
> 先にも書いたとおり、とあるサイトのデータ (の一部) を再帰的に取得したいので、そこから、外部に張られているリンク (相対リンクではない絶対リンク) をたどって欲しくないという意味で、-L を追加したものです。
ということであれば、-np オプションと、-D オプションを使用したほうが
よいかと思います。
http://www.example.org/foo/bar/ 以下のドキュメントを取得するので
あれば、
$ wget -D www.example.org -np -r -l 10 http://www.example.org/foo/bar/
とすれば、外部のホストへのリンク、および上位ディレクトリへのリンクは
辿りません。
なお、/etc/wgetrcなどでspan_hostsがonに設定されていないことは確認して
ください。
# defaultではspan_hostsがoff(='-H'を指定しない状態)になっているはず
# なので、外部ホストへのリンクは辿らないはずですが、Location: ヘッダ
# などで誘導されると、外部ホストへも追跡してしまうようです。
-l オプションについては、ソースを調べたのがかなり以前になるので、
最近の実装がどうなっているか、また何らかの問題があるかもわかりません。