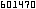wget で robots.txt や meta tag のロボット制御を無視させたいのですが、man wget を見た限り、設定ができないようです。
Cygwin バイナリ, tar ball からの make ともに試しましたが、オプションそのものがないように見受けられます。(strings `which wget` | grep robot)
やりたいことはいわゆる丸ごとダウンロードなのですが、目的は、Web サイトのコンテンツの圧縮ソフトを作ったので、よそ様のサイトでどれくらいの効果があるか、測定したいのです。
curl は再帰回収自体ができませんし、何か代替手段がありましたら、ご教授いただけませんでしょうか。wget 自身の改造を試みたのですが、どうもうまくいきませんでした。
というか、wget -r -L -l 10 url のように -l を指定すると私のところでは正常に再帰回収しないようなのです。バグ? MD5 は、70f0043044029bbbff271a5f5aad169d です。
アドバイスよろしくお願いいたします。
|